
Zeichen – Zeichensätze
Jedem Zeichen ist eine eindeutige Nummer zugeordnet. Diese Zuordnung regelt der „Zeichensatz„ oder „Zeichencode“. Die Bezeichung „Zeichencode“ ist unglücklich gewählt, weil einerseits die komplette Zuordnungstabelle von Zeichen zu Nummern als „der“ Zeichencode verstanden wird, andererseits aber jedes Zeichen „einen“ Zeichencode hat, eben die Nummer des einzelnen Zeichens lt. Codetabelle.
Zeichen (Ziffern, Buchstaben, Sonderzeichen, Steuerzeichen) werden also entsprechend einer Tabelle in binäre Zahlen (Bytes) übersetzt. Diese Tabellen (Codes) könnten prinzipiell willkürlich angelegt werden, sollten aber einheitlich sein, um den Datenaustausch zu ermöglichen. Es gibt leider nicht nur einen Zeichensatz, sondern mehrere unterschiedliche. Arbeiten Computer mit unterschiedlicher Codierung, so müssen Übersetzungsprogramme eingesetzt werden.
ASCII
Die Grundlage für den im PC Bereich eingesetzten Code ist der ASCII (American Standard Code
for Information Interchange), der aus dem Bereich der Nachrichtenübermittlung zwischen Fernschreibern genommen wurde. Dieser Code kam ursprünglich mit 7 bit Information aus. Die Codes aller Zeichen im ASCII-Code liegen im Bereich von 0 bis 127. Der ASCII-Code umfasst Buchstaben, Ziffern, Punktionszeichen usw. Nachdem er von einer amerikanischen Institution verfasst wurde, fehlten z.B. nationale Sonderzeichen europäischer Länder, wie etwa deutsche Umlaute.
Zeichen im ASCII:

- Die ersten 32 Zeichen sind Steuerzeichen für die Kommunikation bzw. nichtdruckbare Zeichen (Zeilenvorschob, Tabulator, …). Die Zeichen mit diesen Codes heißen „Kontrollzeichen“
- Die Zeichen 32 bis 127 beinhalten Ziffern, Buchstaben und Sonderzeichen aus dem englischen Sprachraum
PC-Code
Über den ASCII-Code hinaus gibt es verschiedene andere Codes, die weitere Zeichen enthalten. Diese Codes beruhen auf dem ASCII-Code, weil sie die ersten 128 Zeichen (mit Nummern 0 bis 127) unverändert aus dem ASCII-Code übernehmen, dann aber weitere 128 Zeichen mit Nummern 128 bis 255 anhängen. In dieser „oberen“ Hälfte ist Platz für nationale Sonderzeichen u.ä..
Mit der Einführung des Personal Computers im Jahre 1981 wurde von IBM auch das 8. bit zur Zeichendarstellung verwendet, es entstand der erweiterte ASCII Code (IBM-PCROM-Character Code oder kurz „PC-Code“). Diese lange Zeit übliche Erweiterung von 128 bis 255 beinhalten Sonderzeichen für andere Sprachen (z.B. Umlaute für Deutsch, …), einige griechischen Buchstaben, mathematische Sonderzeichen und Symbole zum Zeichnen von sehr einfachen Grafiken im Textmodus. Die Auswahl muss man allerdings als willkürklich bezeichnen. Die folgende Tabelle zeigt den PC-Code:

ISO-Code
Die International Standards Organisation hat, aufbauend auf den ASCII-Code, verschiedene Erweiterungen definiert, von denen der ISO-8559-Code interessant ist. Die ISO hat sich bemüht,
den Bedürfnissen europäischer Länder Rechnung zu tragen. Die Auswahl der zusätzlichen Zeichen systematischer als etwa beim PC-Code.
In weiterer Folge wurde die iso-8559-Familie wurde vom European Computer Manufacturer’s Association (ECMA) entwickelt. Es handelt sich um ein Set von standardisierten Zeichensätzen für alphabetische Schriften. Dazu gehören die lateinischen Schriften, auf denen die meisten Sprachen Westeuropas und Amerikas beruhen, oder etwa die kyrillischen Schriften. Die folgende Tabelle zeigt den ISO-8559-1-Code:
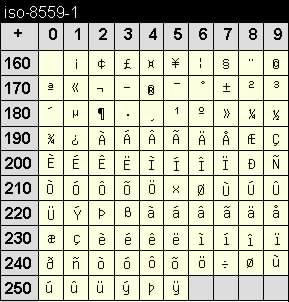
Alle Zeichensätze dieser Familie basieren auf der 1-Byte-Abbildung eines Zeichens. Das heißt, alle Zeichensätze enthalten 256 mögliche Zeichen. Bei allen Zeichensätzen sind die ersten 128 Zeichen, also die Zeichen mit den Werten 0 bis 127, identisch mit dem ASCII-Zeichensatz. Das hat den Vorteil, dass die üblichen lateinischen Groß- und Kleinbuchstaben, die arabischen Ziffern und die üblichen Sonderzeichen wie Satzzeichen oder kaufmännische Zeichen in all diesen Zeichensätzen immer zur Verfügung stehen.
UNICODE
Unicode ist ein System, in dem die Zeichen oder Elemente aller bekannten Schriftkulturen und Zeichensysteme festgehalten werden. Durch dieses System wird es möglich, einem Computer zu sagen, welches Zeichen man dargestellt bekommen will. Voraussetzung ist natürlich, dass der Computer bzw. das ausgeführte Programm das Unicode-System kennt. Viele neuere Rechnertypen und Betriebssysteme basieren intern bereits auf dem Unicode-System. So werden modernen Betriebssystemen alle Zeichen, egal mit welcher Software man arbeitet, im Arbeitsspeicher intern als Unicodes gespeichert.
Jedes Zeichen oder Element in Unicode wird durch eine zwei Byte lange Zahl ausgedrückt. Auf diese Weise lassen sich bis zu 65536 verschiedene Zeichen in dem System unterbringen. In Version 2.0 des Unicode-Standards sind 38885 Zeichen dokumentiert. Es ist also noch Platz genug. Damit es jedoch nicht irgendwann eng wird, gibt es mittlerweile ein erweitertes Schema, mit dem weit über eine Million verschiedene Zeichen in das System passen.
Unicode geht dadurch konsequent über das Prinzip der einzelnen Zeichensätze hinaus. Mit Hilfe dieses Systems ist es beispielsweise möglich, mitten in einem deutschen Text ein paar japanische Wörter zu notieren. Auch für Steuerzeichen wie Silbentrennzeichen, erzwungene Leerzeichen oder Tabulatorzeichen gibt es Unicodes. Die Zeichen mathematischer Formeln fehlen ebensowenig wie die Silben- oder Wortzeichen fernöstlicher Schriftkulturen. Auch Einzelteile von Zeichen, wie etwa die Doppelpunkte über den deutschen Umlauten, haben einen eigenen Unicode. Zeichen lassen sich dynamisch kombinieren – so gibt es zwar natürlich auch ein deutsches „ä“, aber der gleiche Buchstabe lässt sich auch aus „a“ und dem Element für Doppelpunkt über dem Zeichen erzeugen.